Documents
Common general documents for the ESSnet
I3S Roma Hackathon
Minutes
Agenda
Monday 20 May, morning session
- Introduction
- Update on the work done (each WP leader to prepare short presentation)
- Agenda and organization of the week
- Explore more in detail ARC and Relais (short live demos)
- First discussion on ARC-Relais integration (with Laura)
Monday 20 May, afternoon session
- ARC Relais integration
- Presentation of methodology and use case for Relais
- Requirements for reuse, generally and more specifically for ARC and Relais
- Sharing algorithms
Tuesday 21 May, morning session
- Presentation on CSPA work from Toulouse Document
- Brainstorming on the technologies and services for the WP3 platform. Identify capabilities needed in the platform
- Map the result of the brainstorming with a “shortlist” of CSPA-features (scalability, security, sandboxing …) that can be partially or fully implemented by using cloud-capabilities/technologies
- List pros/cons by implementing these features by using cloud-capabilities
- Prioritize between technologies for features that can be implemented using multiple cloud technologies
- Describe how the different services could be implemented by using cloud platforms/technologies (cookbook with examples)
- Setup prioritized plan for implementations.
Tuesday 21 May, afternoon session
- Description of a statistical service generalized architecture
- Presentation of the Relais TO-BE architecture and live demo of the first set of implemented functionalities. Application of the morning results to the Relais example
- Presentation of the ARC architecture. Application of the morning results to the ARC example
- First elements for an unified architecture
Wednesday 22 May to Friday 24 May morning
Three hackathon threads:
- Track 1: prototype of Relais and ARC containerization. Containerization of ARC and Relais. Comprehensive demo of the containerized applications
- Track 2: VTL editor, development of new functionalities. VTL description. How to integrate VTL in ARC. Agreement on the objectives for this integration
- Track 3: success stories. Survey on service reuses. Tools for sharing success stories (audio, video …). Examples in a cookbook
Friday 24 May, closing session
Conclusions of the workshop and next steps:
- Pitches of the three threads
- Overview of Eurostat projects
- Communication at Unece MSW workshop
- Toulouse hackathon
- Roadmap
WP1 - work done
ARC: The current architecture and capabilities have been modelled. The description of the main functionalitites and the data model have been delivered.
Relais: The current architecture and capabilities and the to-be business layer have been modelled. The description of the main functionalities and data model have been delivered.
Relais and ARC integration: An initial assessment of the optimal solutions to integrate RELAIS and ARC functionalities has been done.
PX-Web:
- SCB has done an initial internal planning and harmonization with SSB
- INE has tried PX-web current version, checked requirements to run the upcoming “open” version and assessed the impact on adapting existing dissemination chain
Intentions for this hackathon:
- share the activities and the results achieved
- integrate of work done
- describe and test potential use cases
- POC of hypothesis
- co-operative activities
- share ideas & experiences
WP2 - work done
The deliverable of M6, “Cookbook on integration and use”, is just a draft for the moment (it could be uploaded as such in CROS platform) The first deliverable will be an interactive report/guidance with examples. The version 0.01 has been done from Software & integration architecture recommandations and the M6 deliverable.
Next steps :
- continue creating the structure in architectural recommendations
- check with the other parties
During the Rome-Sprint :
- monitor Track 1 and 2 to gather input for the “cookbook deliverable”
WP3 - work done:
Lack of progress because of a lack of material
During the hackathon:
- try to use Vagrant, but adds extra layers of complexities
- look into docker templates
- tangible deliverables: create a docker container, run it (locally or in the cloud), documentation
- bonus tasks : automate build, features, other things?
WP4 - work done:
A draft version of a questionnaire has been done: aims to know why people are trying to share services but not so willing to consume shared services. During the hackathon, we will have to validate the questionnaire and choose the dissemination tools
There also has been a questionnaire during the last ESSNet. We must see what has been done to be sure that the new questionnaire is different from the last questionnaire. It would be appreciated to have an introductory part explaining what has been done in the last questionnaire.
The questionnaire tool of Eurostat could be used for collect, il will allow to have the ecas authentification.
WP5 - work done
The deliverables D1.1, “List of services to be developed and reused”, and D5.1, “First monitoring report”, have been delivered and validated. The March reporting and April reporting can be found on Github.
The next deliverables are:
- D1.2 Service 1 – July 2019
- D5.2 Monitoring report 2 – July 2019
- D3.2 Package container for Service 1 – August 2019
- D1.4 Service 2 – November 2019
- D5.3 Intermediary report - November 2019
- D3.3 Package container for Sevice 2 – December 2019
By the end of April, the consumed human ressources are 100 days, whereas the total ressources for the project is 900 days.
The possible events where a communication could be done are:
- UNECE ModernStats World Workshop 2019, Geneva, June 26-28
- SDMX Global Conférence 2019, Budapest, September 16-19
- ICES 2020, New Orleans, June 15-18
- ISI 2021, The Hague, July 11–15
- Eurostat meetings (IT WG, DIME/ITDG)
- (ISA² Share and Reuse 2019, Bucharest, June 11)
Arc and Relais integration
ARC is a “service implements extended functionalities for integrating administrative data into statistical processes”. “RELAIS (REcord Linkage At IStat) is a toolkit providing a set of techniques for dealing with record linkage projects.”
Integration points at the business level :
- during the integration phase of ARC, use Relais to link two sources
- at the end of the main ARC process, after validation and editing Integration points at the technical level :
- ARC calls a Relais service through the wire for performing the linkage
- ARC uses a set of Relais methods via Java modules
The work hypothesis is that data exchange between ARC and RELAIS is performed by a data model translator service. Following this approach, we could combine and harmonize the following process steps and related modules of ARC and RELAIS :
- Data loading [ARC]
- Data coding [ARC]
- Data editing and imputation [ARC]
- Derive new variables and units (temporary simple data model) [ARC]
- Probabilistic record linkage [Relais]
- search space reduction
- selection of thresholds
- definition of match, possible match, unmatch subsets
- Derive new variables and units (complex final data model) [ARC]
Presentation of the methodology and use-cases of Relais
It dates back to 2006. Istat needed a tools for probabilistic record linking. RL process is divided into several steps, and different methods are available for each steps.
Presentation on sharing algorithm
Presentation by Matjaz Jug from Statistics Netherland (SN).
The benefits of sharing algorithm are many : transparency, productivity, security, multi-domain approach, standardization and innovation.
CBS has a data strategy based on 4 architectural patterns :
- external data collected and copied to SN
- SN data/algorithm copied to external partner
- data connected/processed virtually
- data/algorithm makes roundtrip
When there are a lot of partners and legal constraints, it is necessary to establish a scalable technical and governance framework which can combine access-restricted data from multiple entities in a privacy-preserving manner.
Answers can be given by the MIT project OPAL :
- Move the algorithm to the data. Performing algorithm-execution on data at the location of the data repository means that raw data never leaves its repository, and access to it is controlled by the repository owner. Only aggregate answers or “Safe Answers” are returned.
- Algorithms must be open. Algorithms must be openly published, studied and vetted by experts to be “safe” from violating privacy requirements and other needs stemming from the context of their use.
- Data is always in an encrypted state. Data must be in an encrypted state while being transmitted and during computation.
Another interesting approach is the UN Global Platform Methods Store, with an algorithm pipeline :
- Identification & Scoping
- Data Exploration & Algorithm Development
- Algorithm Publication & Consumption
Features in the WP3 platform
The discussion is on features of WP3 platform but also on the links between WP2 and WP3. It will focus a little bit on common cloud capabilities to determine which capabilities we want to adopt, but also when it has consequences we don’t want as as CSPA community.
Output from the Toulouse sprint :
- it is necessary to have a plug and play archutecture but also to share the information model between the services to be connected
- in order to share services we have to describe the context in terme of functional requirements (end user oriented), and then in terme of features (non functional requirements)
Preselection for cloud implementation:
- F6: security solutions
- F8: sandboxing for exploration
- F9: containerization
- F10: multiple instances
- F14: service integration
- F15: big data capable
- F16: virtualization
- F19: resilience
Possible connection to cloud implementations :
- CSPA adapters
- versioning
- support for centralized data
- support for decentralized data
- contexte aware
Result of the brainstorming on a Minimum Viable Product for the platform :
- F9 is an answer to portability, but it can be difficult for certain NSIs because of the technological complexity. For managing security, solutions could be white listing and container scanning. It is proposed to have a backbone of the CSPA catalogue with the images of all the services. For a MVP, docker would be a good solution (it is widespread and a defacto standard)
- changing data models is costly, can we use a feature like adapters ?
- priorities: F19 resilience, F8a sandboxing (as in ARC sandboxing), F10 multiple instances, F14 service
The discussion proposed a first sketch of a statistical architectural pattern for a “sandbox” or more accurately a “workbench”.
Description of a statistical service generalized architecture
The objectives of a statistical service is to perform the following tasks:
- Upload and manage input data, to provide initial data to process
- Parameters and variables settings
- Run method
- Analyse output
Seen as such, a statistical service can be mapped to GSIM by using the objects “Business Function”, “Business Process” and “Process step”.
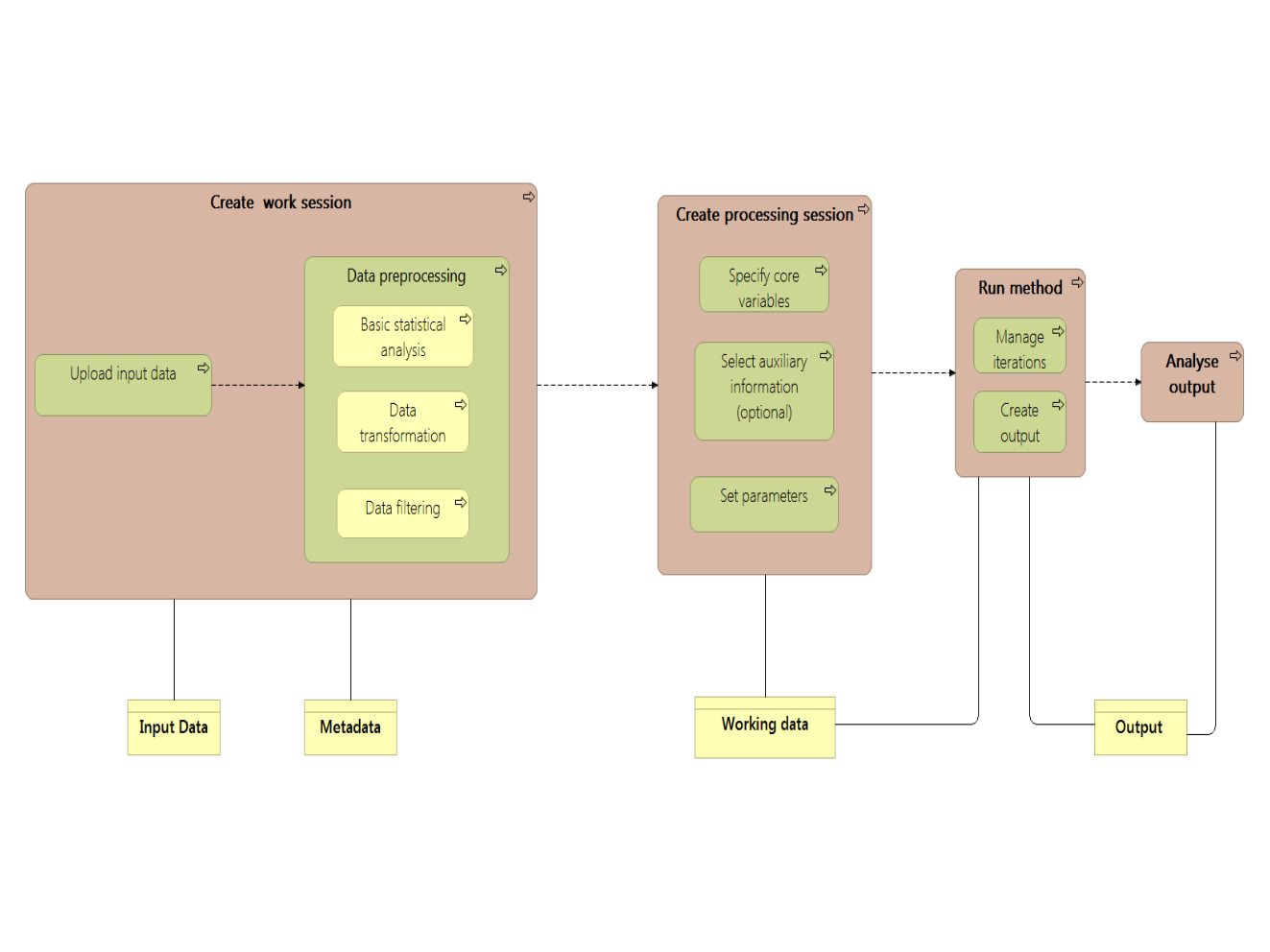
And at application level :
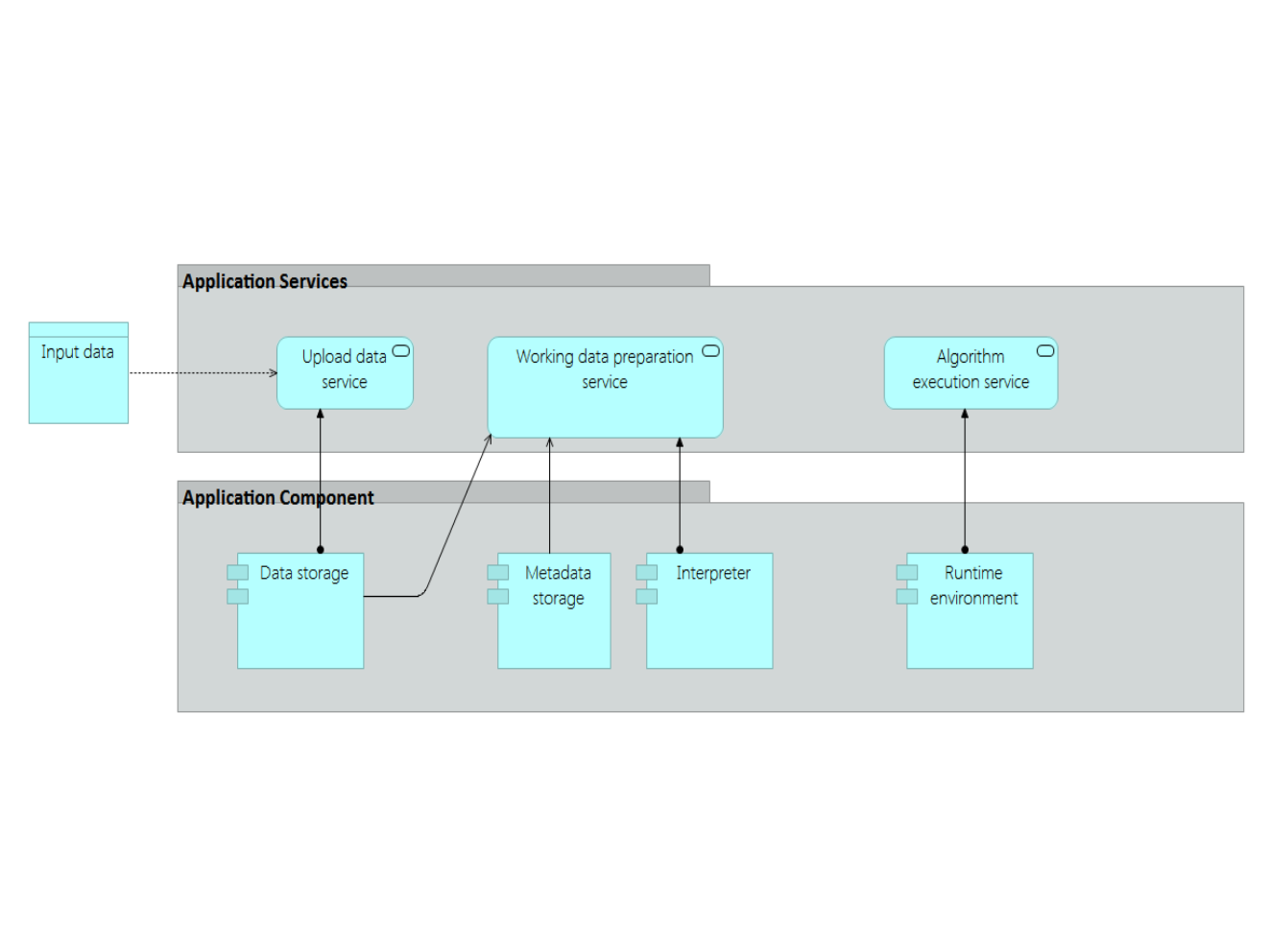
Conclusion of thread 1
Work planned :
- Dockerize the IS2 application: a first container for the Spring Boot application, a second one for the database
- Deploy both containers: the target platforms could be Compose, a cloud provider, etc.
Work done:
- deployment using Docker compose
- deployment on the DCOS Insee platform
- in both cases using images pushed to Docker Hub
- also as a by product, update of the version of Spring boot
- everything is on GitHub and on Docker hub
Next steps:
- integrate the Spring boot update to the code base
- deploy on a cloud provider, using Kubernetes
- document the work and the lessons learned for WP3
Conclusion of thread 2
The objective is to agree on how to integrate VTL in ARC.
There is an existing norwegian VTL-tool. The french use cases will be :
- use VTL as a formal language to express rules
- use VTL for data validation
The general context is to use VTL to express rules and execute them in web questionnaires and for administrative sources (GSBPM phase: data collection).
At logical level:
- analysis of the requirements in CSPA terms
- express the controls in VTL
- execute the controls in VTL
At technical level:
- coding the grammar
- coding the connector
- coding the React control
Conclusion of thread 3
The questionnaire for analysing the main incentives and impediments for sharing has been validated.
A first version of a all-in-one poster has been proposed. This poster is exploring the questions : how to break barriers from not reuse to reuse ? how to promote from not share to share ?
Content of a communication kit:
- Selected success stories could be: JDemetra+ and PX-web…
- Story about lessons learnt: Eno
- Include interviews with: software or service producers, software users
- With linked stories to graphic presentations at management, production dept., dev. teams)
- Make a Poster for conferences
- … and a world map of reusing
Options for wideo presentations:
- Share on YouTube
- How? Create a new channel? Reuse an existing channel?
- Use PowToon?
- Use Prezi?
Eurostat projects
- Business case for Eurostat: lots of input data as files, multiple file formats, high number of potentially big files to process
- Two CONVAL stacks: Oracle/WebLogics and Open source (Tomcat/Postgres). Predefined Docker images. Standalone intaller is being phased out.
- Plans for VTL 2: 5 iterations (defined by list of operators), planned until mid-2020. Usable product after iteration 2.
- Developement of the VRM (Validation Rule Manager)
- VTL: considerable input from Istat and Banca d’Italia
- work in Norway, Poland, Finland, Italie, and the BCE (BIRD project, mostly for validation)
- VTL / SDMX integration: tweak the SDMX IM in order to adapt it to VTL, and replace the transformation part of SDMX with VTL. That would be in SDMX 3.0 since it requires changes in the IM. Target is end of 2020.
- Creation of a standard validation report structure (building on a proposal of the Validation ESSnet, spearheaded by CBS). Will be structured as an SDMX MSD.
- Bringing it all together: standardization vs development community; central banking vs statistical community; SDMX community vs the rest of the world.